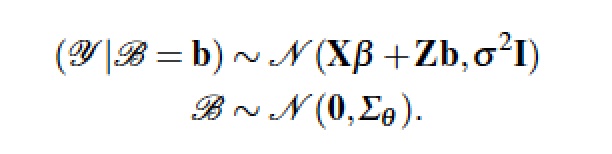First, I will review the examples I have already used and in future posts introduce a few more. When I develop equations, there is an interaction between how I write the equations and how I know I will have to write simulation code to generate data for the model. Until I actually show you how to write that R code in a future post, I'm going to use pseudo-code, that is, an English language (rather than machine readable) description of the algorithm necessary to generate the data. If you have not written pseudo-code before, Wikipedia provides a nice description with a number of examples of "mathematical style pseudo-code" (here).
For the Dyestuff example (here and here) we were "provided" six "samples" representing different "batches of works manufacturer." The subtle point here is that we are not told that the batches were randomly sampled from the universe of all batches we might receive at the laboratory (probably an unrealistic and impossible sampling plan). So, we have to deal with each batch as a unit without population characteristics. So, I can start with the following pseudo-code:
For (Every Batch in the Sample)
For (Every Observation in the Batch)
Generate a Yield coefficient from a batch distribution.
Generate a Yield from a sample distribution.
End (Batch)
End (Sample)
If we had random sampling, I would have been able to simply generate a Yield from a sample Yield Coefficient and a sample Yield distribution (the normal regression model). What seems difficult for students is that many introductory regression texts are a little unclear about how the data were generated. On careful examination, examples turn out to not have been randomly sampled from some large population. Hierarchical models, and the attempt to simulate the underlying data generation process, sensitize us to the need for a more complicated representation. So, instead of the single regression equation we get a system of equations:

The second model I introduced was the Black Friday Sales model (here). I assumed that we have yearly weekly sales data and Black Friday week sales generated at the store level. I also assume that we have retail stores of different sizes. In the real world, not only do stores of different sizes have different yearly sales totals but they probably have somewhat different success with Black Friday Sales events (I always seem to see crazed shoppers crushing into a Walmart store at the stroke of midnight, for example here, rather than pushing their way into a small boutique store). For the time being, I'll assume that all stores have the same basic response to Black Friday Sales just different levels of sales. In pseudo-code:
For (Each Replication)
For (Each Size Store)
For (Each Store)
Generate a random intercept term for store
Generate Black Friday Sales from some distribution
Generate Yearly Sales using sample distribution
End (Store)
End (Store Size)
End (Replication)
and in equations
where the terms have meanings that are similar to the Dyestuff example.
I showed the actual R code for generating a Black Friday Sales data set in the last post (here). The two important equations to notice within the outer loops are
b0 <- b[1] - store + rnorm(1,sd=s[1])
yr.sales <- b0 + b[2]*bf.sales + rnorm(1,sd=s[2])
The first gets the intercept term using a normal random number generator and the second forecasts the actual yearly sales using a second normal random number generator. The parameters to the function rnorm(1,sd=s[1],mean=0) tell the random number generator to generate one number with mean zero (the default) and standard deviation given s[1]. For more information on the random number generators in R type
> help(rnorm)
after the R prompt (>). In a later post I will describe how to generate random numbers from any arbitrary or empirically generated distribution using the hlmmc package. For now, standard random numbers will be just fine.
In the next post I'll describe in more detail how to generate the Dyestuff data.