Two earlier posts (here and here) described a simple hierarchical linear model (HLM) for Black Friday Retail Sales using data from an article in the Washington Post (here). The pedagogical purpose of the HLM exercise was to display one answer to Simpson's Paradox. It wasn't meant to be a general recommendation for the analysis of retail sales.
The analysis of aggregate retail sales is essentially a time series problem in that we are analyzing sales over time for, ideally, multiple years. HLMs can be written to handle time series problems, a topic that I will return to in a later post. The analysis of aggregate US retail sales, however, can be analyzed with a straight-forward state space time series model. If you are interested in the pure time series approach, I have done that in another post (here).
The insight from the time series analysis is that US Retail Sales are being driven by the World economy which makes sense in a world of globalized retail trade. The idea that Black Friday Sales might be a good predictor of aggregate retail sales is, based on purely theoretical considerations, not a very appealing hypothesis.
Showing posts with label HLM. Show all posts
Showing posts with label HLM. Show all posts
Friday, December 28, 2012
Friday, December 7, 2012
How to Write Hierarchical Model Equations
In the last few posts (here and here) I've written out systems of equations for hierarchical models. So far, I've written out equations for the Dyestuff and the Black Friday Sales models. Hopefully, it's easy to follow the equations once they are written out. Starting from scratch and writing your own equations might be another matter. In this post I will work through some examples that should give some idea about how to start.
First, I will review the examples I have already used and in future posts introduce a few more. When I develop equations, there is an interaction between how I write the equations and how I know I will have to write simulation code to generate data for the model. Until I actually show you how to write that R code in a future post, I'm going to use pseudo-code, that is, an English language (rather than machine readable) description of the algorithm necessary to generate the data. If you have not written pseudo-code before, Wikipedia provides a nice description with a number of examples of "mathematical style pseudo-code" (here).
For the Dyestuff example (here and here) we were "provided" six "samples" representing different "batches of works manufacturer." The subtle point here is that we are not told that the batches were randomly sampled from the universe of all batches we might receive at the laboratory (probably an unrealistic and impossible sampling plan). So, we have to deal with each batch as a unit without population characteristics. So, I can start with the following pseudo-code:
For (Every Batch in the Sample)
For (Every Observation in the Batch)
Generate a Yield coefficient from a batch distribution.
Generate a Yield from a sample distribution.
End (Batch)
End (Sample)
If we had random sampling, I would have been able to simply generate a Yield from a sample Yield Coefficient and a sample Yield distribution (the normal regression model). What seems difficult for students is that many introductory regression texts are a little unclear about how the data were generated. On careful examination, examples turn out to not have been randomly sampled from some large population. Hierarchical models, and the attempt to simulate the underlying data generation process, sensitize us to the need for a more complicated representation. So, instead of the single regression equation we get a system of equations:

where lambda_00 is the yield parameter, mu_0j is the batch error term, beta_0j is the "random" yield coefficient, X is the batch (coded as a dummy variable matrix displayed here), epsilon_ij is the sample error and Y_ij is the observed yield. With random sampling, beta_0j would be "fixed under sampling" at the sample level. Without random sampling, it is a "random coefficient". Here, the batch and the sample distributions are both assumed to be normal with mean 0 and standard errors sigma_u0 and sigma_e, respectively. I'll write the actual R code to simulate this data set in the next post.
The second model I introduced was the Black Friday Sales model (here). I assumed that we have yearly weekly sales data and Black Friday week sales generated at the store level. I also assume that we have retail stores of different sizes. In the real world, not only do stores of different sizes have different yearly sales totals but they probably have somewhat different success with Black Friday Sales events (I always seem to see crazed shoppers crushing into a Walmart store at the stroke of midnight, for example here, rather than pushing their way into a small boutique store). For the time being, I'll assume that all stores have the same basic response to Black Friday Sales just different levels of sales. In pseudo-code:
For (Each Replication)
For (Each Size Store)
For (Each Store)
Generate a random intercept term for store
Generate Black Friday Sales from some distribution
Generate Yearly Sales using sample distribution
End (Store)
End (Store Size)
End (Replication)
and in equations

where the terms have meanings that are similar to the Dyestuff example.
I showed the actual R code for generating a Black Friday Sales data set in the last post (here). The two important equations to notice within the outer loops are
b0 <- b[1] - store + rnorm(1,sd=s[1])
yr.sales <- b0 + b[2]*bf.sales + rnorm(1,sd=s[2])
The first gets the intercept term using a normal random number generator and the second forecasts the actual yearly sales using a second normal random number generator. The parameters to the function rnorm(1,sd=s[1],mean=0) tell the random number generator to generate one number with mean zero (the default) and standard deviation given s[1]. For more information on the random number generators in R type
> help(rnorm)
after the R prompt (>). In a later post I will describe how to generate random numbers from any arbitrary or empirically generated distribution using the hlmmc package. For now, standard random numbers will be just fine.
In the next post I'll describe in more detail how to generate the Dyestuff data.
First, I will review the examples I have already used and in future posts introduce a few more. When I develop equations, there is an interaction between how I write the equations and how I know I will have to write simulation code to generate data for the model. Until I actually show you how to write that R code in a future post, I'm going to use pseudo-code, that is, an English language (rather than machine readable) description of the algorithm necessary to generate the data. If you have not written pseudo-code before, Wikipedia provides a nice description with a number of examples of "mathematical style pseudo-code" (here).
For the Dyestuff example (here and here) we were "provided" six "samples" representing different "batches of works manufacturer." The subtle point here is that we are not told that the batches were randomly sampled from the universe of all batches we might receive at the laboratory (probably an unrealistic and impossible sampling plan). So, we have to deal with each batch as a unit without population characteristics. So, I can start with the following pseudo-code:
For (Every Batch in the Sample)
For (Every Observation in the Batch)
Generate a Yield coefficient from a batch distribution.
Generate a Yield from a sample distribution.
End (Batch)
End (Sample)
If we had random sampling, I would have been able to simply generate a Yield from a sample Yield Coefficient and a sample Yield distribution (the normal regression model). What seems difficult for students is that many introductory regression texts are a little unclear about how the data were generated. On careful examination, examples turn out to not have been randomly sampled from some large population. Hierarchical models, and the attempt to simulate the underlying data generation process, sensitize us to the need for a more complicated representation. So, instead of the single regression equation we get a system of equations:

The second model I introduced was the Black Friday Sales model (here). I assumed that we have yearly weekly sales data and Black Friday week sales generated at the store level. I also assume that we have retail stores of different sizes. In the real world, not only do stores of different sizes have different yearly sales totals but they probably have somewhat different success with Black Friday Sales events (I always seem to see crazed shoppers crushing into a Walmart store at the stroke of midnight, for example here, rather than pushing their way into a small boutique store). For the time being, I'll assume that all stores have the same basic response to Black Friday Sales just different levels of sales. In pseudo-code:
For (Each Replication)
For (Each Size Store)
For (Each Store)
Generate a random intercept term for store
Generate Black Friday Sales from some distribution
Generate Yearly Sales using sample distribution
End (Store)
End (Store Size)
End (Replication)
and in equations
where the terms have meanings that are similar to the Dyestuff example.
I showed the actual R code for generating a Black Friday Sales data set in the last post (here). The two important equations to notice within the outer loops are
b0 <- b[1] - store + rnorm(1,sd=s[1])
yr.sales <- b0 + b[2]*bf.sales + rnorm(1,sd=s[2])
The first gets the intercept term using a normal random number generator and the second forecasts the actual yearly sales using a second normal random number generator. The parameters to the function rnorm(1,sd=s[1],mean=0) tell the random number generator to generate one number with mean zero (the default) and standard deviation given s[1]. For more information on the random number generators in R type
> help(rnorm)
after the R prompt (>). In a later post I will describe how to generate random numbers from any arbitrary or empirically generated distribution using the hlmmc package. For now, standard random numbers will be just fine.
In the next post I'll describe in more detail how to generate the Dyestuff data.
Sunday, October 14, 2012
HLMs: The ML Estimator
In a prior post (here) I wrote out two models for the Dyestuff data set. The first model was a simple regression model and the second model was a hierarchical, random-coefficients model. I first estimated the simple regression model which does not contain random components. In this post, I will estimate the standard Maximum Likelihood (ML) model used to fit random components and hierarchal models.
The lme4 package has been developed by Doug Bates at the University of Wisconsin and is considered state-of-the-art for ML estimation of mixed models, that is, models with both fixed and random effects, such as hierarchical models. Package documentation is available here, draft chapters of a book on lme4 are available here and an excellent presentation on lme4 given at the UseR!2008 Conference is available here.
In Chapter 1 of the lme4() book, Doug Bates is careful to clear up the terminological problems that have plagued the statistics literature:


In the HLM-form of the Dyestuff model, the matrix Z codes different manufacturers, the second level variable. When we solve the model in the third equation above we see that an interaction term between ZX has been added to the model.

Laird and Ware (1982) (you can find the article here, but let me know if this link is broken) develop another popular form of the model in the equations above. In Stage 2, as they call the second level, the b matrix of unknown individual effects is distributed normally with covariance matrix D. The population parameters, the alpha matrix, are treated as fixed effects. In Stage 1, each individual unit i follows the second equation above: e is distributed N(0,R) where R is the covariance matrix. At this stage, the alpha and the beta matrices are considered fixed.
In the marginal distribution, (y | b), the y are also independent normals with covariance matrix R + Z D Z' where R, under conditions of conditional independence, can be simplified to an identity matrix with a single standard error, sigma.
The Laird and Ware (1982) article is worth detailed study. They present not only the ML model but also the Bayesian approach that leads to the restricted maximum likelihood (REML) estimator. And, they explain clearly how the EM (expectation-maximization) algorithm can be used to solve the model. The EM algorithm treats the individual characteristics of random effects models as missing data where the expected value replaces each missing data element after which the effects are re-estimated until the likelihood is maximized. I will talk about the EM algorithm in a future post because it is the best approach to deal generally with missing data.
 Finally, we get to Doug Bates' notation, which should be clearer now that we have presented the Laird and Ware model. What is important to note is that Doug assumes conditional independence.
Finally, we get to Doug Bates' notation, which should be clearer now that we have presented the Laird and Ware model. What is important to note is that Doug assumes conditional independence.
Although I love matrix algebra, for HLMs I prefer to write out models explicitly in non-matrix terms as was done in the first set of equations above. In the lme4 package, my students have found the notation for specifying the random components of the model in the Z matrix to be somewhat confusing. Returning to the single-equation HLM form of their models has help to clear up the confusion.
The lme4 package has been developed by Doug Bates at the University of Wisconsin and is considered state-of-the-art for ML estimation of mixed models, that is, models with both fixed and random effects, such as hierarchical models. Package documentation is available here, draft chapters of a book on lme4 are available here and an excellent presentation on lme4 given at the UseR!2008 Conference is available here.
In Chapter 1 of the lme4() book, Doug Bates is careful to clear up the terminological problems that have plagued the statistics literature:
- Mixed-Effects Models describe a relationship between a response (dependent) variable and the covariates (independent variables). However, a mixed-effects model contains both fixed- and random-effects as independent variables. Furthermore, one of the covariates must be a categorical variable representing experimental or observational units (the units of analysis).
- Fixed-effect Parameters are parameters associated with a covariate that is fixed and reproducible, meaning under experimental control.
- Random Effects are levels of a covariate that are a random sample from all possible levels of the covariate that might have been included in the model.

To me, the confusion is cleared up by returning to the model and considering the terminology an attribute of the model rather than the data. In the model above, lambda 00 is the fixed effect and mu 0j is the random effect which is simply the error term on the first equation. Since both mu 0j and epsilon ij are error terms, they are not parameters in the model. On the other hand, sigma u0 and sigma e are parameters. Still confused?
What I will argue repeatedly in remaining posts is that the way you determine what is or is not a parameter is through Monte Carlo simulation. For a given model, terms that must be fixed before you can run the simulation are parameters. Other terms in the model are random variables, that is, simulation variables that we will have to generate from some density function. What I insist to my students is that you cannot use input data to run the Monte Carlo simulation. In order for the simulation to work without input data, you must be clear about (and often surprised by) the actual random variables in your model.
Before I present the ML model in the notation Doug Bates is using, let's return to the expanded Dyestuff hierarchical model introduced earlier.


In the marginal distribution, (y | b), the y are also independent normals with covariance matrix R + Z D Z' where R, under conditions of conditional independence, can be simplified to an identity matrix with a single standard error, sigma.
The Laird and Ware (1982) article is worth detailed study. They present not only the ML model but also the Bayesian approach that leads to the restricted maximum likelihood (REML) estimator. And, they explain clearly how the EM (expectation-maximization) algorithm can be used to solve the model. The EM algorithm treats the individual characteristics of random effects models as missing data where the expected value replaces each missing data element after which the effects are re-estimated until the likelihood is maximized. I will talk about the EM algorithm in a future post because it is the best approach to deal generally with missing data.
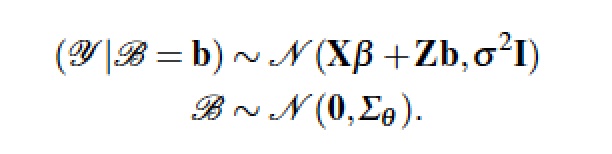
Although I love matrix algebra, for HLMs I prefer to write out models explicitly in non-matrix terms as was done in the first set of equations above. In the lme4 package, my students have found the notation for specifying the random components of the model in the Z matrix to be somewhat confusing. Returning to the single-equation HLM form of their models has help to clear up the confusion.
> fm1 <- lmer(Yield ~ 1 + (1|Batch),Dyestuff)
> summary(fm1)
Linear mixed model fit by REML
Formula: Yield ~ 1 + (1 | Batch)
Data: Dyestuff
AIC BIC logLik deviance REMLdev
325.7 329.9 -159.8 327.4 319.7
Random effects:
Groups Name Variance Std.Dev.
Batch (Intercept) 1764.0 42.001
Residual 2451.3 49.510
Number of obs: 30, groups: Batch, 6
Fixed effects:
Estimate Std. Error t value
(Intercept) 1527.50 19.38 78.81
The Dyestuff model is specified in the lme4() procedure with the equation Yield ~ 1 + (1|Batch). The random effects in the parentheses are read "the effect of Batch given the grand mean". It may seem strange to find the grand mean (represented by the 1) specified twice in a model. Going back to the single equation HLM form, notice that there are two constants, lambda 00 and the first element of the beta 0 j matrix, thus the two grand means.
Moving beyond the notation to the estimated values, we have two standard errors (42.001, and 49.510) and one fixed effect parameters, 1527.50 with standard error 19.38. The "Random effects: Residual" is the same residual standard deviation, 49.510, as from the OLS ANOVA. That's a little disconcerting because, they way the initial model was written, it would seem that the residual standard deviation should be smaller when we have taken the random error components out of the OLS estimate.
> coef(m1)[1] + mean(coef(m1)[2:6])
(Intercept)
1532
The fixed effect mean is very similar to the average of the OLS coefficients. So, all this heavy machinery was developed to generate the one number, 42.001. Here's my question: "Is this the right number?" I will argue in the next post that the only way to answer this question is through Monte Carlo simulation.
NOTE: Another way to think about random and fixed effects is to think about the problem of prediction. If we want to predict the Yield we might get from a future batch of dyestuff from some manufacturer, all we have to work with are the fixed part of the models. The random components are unique to the sample and will not be reproduced in future samples. We can use the standard deviations and the assumed density functions (usually normal) to compute confidence intervals, but the predicted mean values can only be a function of the fixed effects.
NOTE: Another way to think about random and fixed effects is to think about the problem of prediction. If we want to predict the Yield we might get from a future batch of dyestuff from some manufacturer, all we have to work with are the fixed part of the models. The random components are unique to the sample and will not be reproduced in future samples. We can use the standard deviations and the assumed density functions (usually normal) to compute confidence intervals, but the predicted mean values can only be a function of the fixed effects.
Monday, September 24, 2012
The Dyestuff Model
In a prior post (here), I introduced the Dyestuff data set. At first, one might be tempted to run an analysis of variance (ANOVA) on this data since the stated intention is to analyze variation from batch to batch. The ANOVA model is equivalent to the standard regression model.

Here, all the terms represent matrices: Y is an (n x 1) matrix of dependent variables, Yield in this case. X is an (n x m) design matrix (to be explained in the NOTE below) coding the Batch. The beta matrix is a (m x 1) matrix of unknown coefficients. And, the e matrix is an (n x 1) matrix of unknown errors (departures from perfect fit) distributed normally with mean zero and a single variance, sigma. If your matrix algebra is weak, R provides a great environment for learning linear algebra (see for example here).
The regression model is completely equivalent to ANOVA. You can convince yourself of this by running the two analyses in R.
In R, the anova(m1) command produces the same results as summary(m1), only the results are presented as the standard ANOVA table.
The naive regression result finds that the means of Batches C and E are significantly different from the other batches. What the result says for the initial question is that most batches are +/- 31.31 units from the average yield of 1505. However, some batches can be significantly outside this range. But, is this an analysis of means or analysis of variances? The history and development of terminology (analysis-of-variance, analysis of means, random error terms, random components, random effects, etc.) makes interesting reading that I will explore in a future post. To maintain sanity, it's important to keep focused on the model rather than the terminology.
If we write out another model that might have generated this data, it becomes easier to clarify terminology and understand why ANOVA (analysis of means) might not be the right approach to analyze the variation from batch to batch.



The regression model is completely equivalent to ANOVA. You can convince yourself of this by running the two analyses in R.
> m1 <- lm(Yield ~ Batch,Dyestuff,x=TRUE)
> summary(m1)
Call:
lm(formula = Yield ~ Batch, data = Dyestuff, x = TRUE)
Residuals:
Min 1Q Median 3Q Max
-85.00 -33.00 3.00 31.75 97.00
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1505.00 22.14 67.972 < 2e-16 ***
BatchB 23.00 31.31 0.735 0.46975
BatchC 59.00 31.31 1.884 0.07171 .
BatchD -7.00 31.31 -0.224 0.82500
BatchE 95.00 31.31 3.034 0.00572 **
BatchF -35.00 31.31 -1.118 0.27474
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 49.51 on 24 degrees of freedom
Multiple R-squared: 0.4893, Adjusted R-squared: 0.3829
F-statistic: 4.598 on 5 and 24 DF, p-value: 0.004398
> anova(m1)
Analysis of Variance Table
Response: Yield
Df Sum Sq Mean Sq F value Pr(>F)
Batch 5 56358 11271.5 4.5983 0.004398 **
Residuals 24 58830 2451.2
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
In R, the anova(m1) command produces the same results as summary(m1), only the results are presented as the standard ANOVA table.
The naive regression result finds that the means of Batches C and E are significantly different from the other batches. What the result says for the initial question is that most batches are +/- 31.31 units from the average yield of 1505. However, some batches can be significantly outside this range. But, is this an analysis of means or analysis of variances? The history and development of terminology (analysis-of-variance, analysis of means, random error terms, random components, random effects, etc.) makes interesting reading that I will explore in a future post. To maintain sanity, it's important to keep focused on the model rather than the terminology.
If we write out another model that might have generated this data, it becomes easier to clarify terminology and understand why ANOVA (analysis of means) might not be the right approach to analyze the variation from batch to batch.

Since we have no control over the sampling of batches, we expect that the Yield coefficient will have a random source of variation in addition to the true population yield (see the first equation above). Under normal experimental conditions we might try to randomize away this source of variation by sampling batches for a wide range of suppliers. But, since we are actually not using random assignment, we have a unique source of variation associated with the yield of each batch. As can be seen from the first equation above, this is where the term random coefficients comes from. Where we have random sampling, the effect of Batch on Yield would be a fixed effect, that is, fixed under sampling. In this model, the fixed effect is lambda_00 rather than the usual beta.
The equation that determines Yield (the second and third equations above) thus has a random coefficient. If we substitute Equation 1 into Equation 2, we get Equation 4. Notice that we now have a larger error term, one error associated with Batch and another associated with the model. The purpose of hierarchical modeling is to account for the source of error associated with how the Batches are generated. The "analysis of variance" here involves the two sigma parameters, sigma_u0 (the standard error of the yield coefficient) and sigma_e (the standard error of the regression).
What you might be asking yourself right now is "If this is a HLM, where's the hierarchy?" Let's assume that we were receiving batches from more than one manufacturer. Then, we would have batches nested within suppliers, but still no random sampling. To account for the effect of supplier, we need another second-level variable (second level in the hierarchy), Z, that is an indicator variable identifying the manufacturer.

The organizational chart above makes the hierarchy explicit. If we take the Z out of the model, however, we are still left with a random coefficients model. Since most human activity is embedded within some social hierarchy, it is hard to find a unit of analysis that is not hierarchical: (1) students within class rooms, classrooms within schools, schools within school systems, etc., (2) countries nested within regions, (3) etc. When these implicit hierarchies are not modeled, a researcher can only hope that the second-level random effects are small.
Returning to terminology for a moment, if we were just interested in the analysis of means, then standard ANOVA models (sometimes called Type I ANOVA) gives us a fairly good analysis of differences in Yield. We might have more error associated with the non-random Batches in the error term, but we still have significant results (some Batches have significantly different means in spite of the unanalyzed sources of Batch variance). However, if we are interested in true analysis of variance (sometimes called Type II ANOVA) and if we expect that there is some unique source of variation associated with Batches that we want to analyze, we need a technique that will produce estimates of both sigma_u0 (the standard error of the yield coefficient) and sigma_e (the standard error of the regression).
There are multiple techniques that will perform a Type II ANOVA or random coefficients analysis. In the next post I'll discuss the most popular approach, Maximum Likelihood Estimation (MLE).
NOTE: The equivalence of ANOVA and regression becomes a little clearer by looking at the design matrix for the Dyestuff model. Most students are familiar with the standard regression model where the independent variable, X, is an (n x 1) matrix containing values for a continuous variable. This is how the difference between ANOVA and regression is typically explained in introductory text books. However, if the X matrix contains dummy [0,1] variables coding each Batch, the regression model is equivalent to ANOVA. Here is the design matrix, as the ANOVA X matrix is often called, for the Dyestuff model:
> m1$x
(Intercept) BatchB BatchC BatchD BatchE BatchF
1 1 0 0 0 0 0
2 1 0 0 0 0 0
3 1 0 0 0 0 0
4 1 0 0 0 0 0
5 1 0 0 0 0 0
6 1 1 0 0 0 0
7 1 1 0 0 0 0
8 1 1 0 0 0 0
9 1 1 0 0 0 0
10 1 1 0 0 0 0
11 1 0 1 0 0 0
12 1 0 1 0 0 0
13 1 0 1 0 0 0
14 1 0 1 0 0 0
15 1 0 1 0 0 0
16 1 0 0 1 0 0
17 1 0 0 1 0 0
18 1 0 0 1 0 0
19 1 0 0 1 0 0
20 1 0 0 1 0 0
21 1 0 0 0 1 0
22 1 0 0 0 1 0
23 1 0 0 0 1 0
24 1 0 0 0 1 0
25 1 0 0 0 1 0
26 1 0 0 0 0 1
27 1 0 0 0 0 1
28 1 0 0 0 0 1
29 1 0 0 0 0 1
30 1 0 0 0 0 1
attr(,"assign")
[1] 0 1 1 1 1 1
attr(,"contrasts")
attr(,"contrasts")$Batch
[1] "contr.treatment"
Notice that there is no BatchA, since it plays the role of the reference class to which other batches are compared. That is, the coefficients attached to BatchB through BatchF are expressed as deviations from the grand mean (this construction is necessary because there are only 6 parameters and 6 degrees of freedom, so one class has to become the grand mean).
Saturday, September 22, 2012
A Simple HLM: The Dyestuff Example
Hierarchical Linear Models (HLMs) have their own terminology that challenges a lot of what is taught as basic statistics. We have random effects, random coefficients, and mixed-models added on to what we already know about random error terms and fixed effects. It will help to start with a simple data set that so we can introduce new terms one at a time.
The lme package in the R programming language has a simple data set that provides a good starting point. If you have R running on your machine and the lme package installed, typing help(Dyestuff) produces the following description of the data set:
The
Dyestuff data frame provides the yield of dyestuff (Naphthalene Black 12B) from 5 different preparations from each of 6 different batchs of an intermediate product (H-acid).
The
Dyestuff data are described in Davies and Goldsmith (1972) as coming from “an investigation to find out how much the variation from batch to batch in the quality of an intermediate product (H-acid) contributes to the variation in the yield of the dyestuff (Naphthalene Black 12B) made from it. In the experiment six samples of the intermediate, representing different batches of works manufacture, were obtained, and five preparations of the dyestuff were made in the laboratory from each sample. The equivalent yield of each preparation as grams of standard colour was determined by dye-trial.”
Notice that the batches are not randomly chosen out of some universe of manufactured batches. They are whatever we were able to "obtain". Just to make things concrete, here are the first few lines of the file printed by the R head() command (the > before the head command is the R prompt):
At first, one might be tempted to run an analysis of variance (ANOVA) on this data since the stated intention is to analyze variation from batch to batch. However, there are issues presented by this simple data set that help us understand the added complexity and potential benefits of hierarchical modeling.
In general, the standard approach is to move directly from a data set to some kind of estimator. In the next few posts, I will argue that the standard approach misses a number of important opportunities.
> head(Dyestuff)
Batch Yield
1 A 1545
2 A 1440
3 A 1440
4 A 1520
5 A 1580
6 B 1540
At first, one might be tempted to run an analysis of variance (ANOVA) on this data since the stated intention is to analyze variation from batch to batch. However, there are issues presented by this simple data set that help us understand the added complexity and potential benefits of hierarchical modeling.
In general, the standard approach is to move directly from a data set to some kind of estimator. In the next few posts, I will argue that the standard approach misses a number of important opportunities.
Sunday, September 16, 2012
The 'hlmmc' package
From July 1 through August 15, I taught Sociology S534 Advanced Sociological Analysis: Hierarchical Linear Models at the University of Tennessee in Knoxville. A syllabus for the course is available here. Over the next few months I will serialize the lectures and a user guide for the software package ('hlmmc') used in the course. 'hlmmc' is a software package written in the R programming language for studying Hierarchical Linear Models (HLMs) using Monte Carlo simulation. A manual for the software package is available here. It explains how to download the software and how each function in the package can be used (also, see NOTE below).
The approach I used in the course was to write out the equations for each linear model as a function in the R programming language. The functions were designed so that data for the study could be simulated for each observation in the sample. This is a useful exercise because it forces you to confront a number of difficult issues. What statistical distributions will be used to not only simulate the distributions of the error terms but also the distributions of the independent variables? Typically, a normal distribution is chosen for the error terms and the distributions of the independent variables are ignored in planning a study. Monte Carlo Simulation forces the researcher to confront these issues in addition to explicitly stating the functional form of the model, the actual parameters in the model and a likely range for the parameter values that might be encountered in practice.
In the next posting I'll start with a very simple hierarchical data set and develop an R function for simulating data from a model that could be used to generate similar data. The Monte Carlo function frees us from the sample data and lets us explore more general issues raised by the model. The pitch to my students was that the Monte Carlo approach would provide a deeper understanding of the issues raised by hierarchical models.
The basic feedback from students was that, in the short time available for the class, they were able to get a deeper understanding of HLMs than if the class had be structured as a conventional statistics class (math lectures and exercises?). One student comment in the course evaluations that s/he "...wished all stat classes were taught this way." For better or worse, my classes always have been.
If you are interested in the topic and want to follow the serialization in future postings, I will try to follow my lectures, which were live programming demonstrations, as closely as possible keeping in mind some of the questions and problems my students had when confronting the material.
NOTE: Assuming you have R installed on your machine and you have downloaded the files LibraryLoad.R and HLMprocedures.R to some folder on you local machine, you can load the libraries and procedures using the following commands in R:
where > is the R prompt and W is the absolute path to the working directory where you downloaded the files LibraryLoad.R and HLMprocedures.R. The Macintosh and Windows version of R have 'Source' selection in the File menu that will also allow you to navigate your directory to the folder where these two files have been downloaded. When you source the LibraryLoad.R file, error messages will be produced if you have not installed the supporting libraries listed in the manual (here).
The approach I used in the course was to write out the equations for each linear model as a function in the R programming language. The functions were designed so that data for the study could be simulated for each observation in the sample. This is a useful exercise because it forces you to confront a number of difficult issues. What statistical distributions will be used to not only simulate the distributions of the error terms but also the distributions of the independent variables? Typically, a normal distribution is chosen for the error terms and the distributions of the independent variables are ignored in planning a study. Monte Carlo Simulation forces the researcher to confront these issues in addition to explicitly stating the functional form of the model, the actual parameters in the model and a likely range for the parameter values that might be encountered in practice.
In the next posting I'll start with a very simple hierarchical data set and develop an R function for simulating data from a model that could be used to generate similar data. The Monte Carlo function frees us from the sample data and lets us explore more general issues raised by the model. The pitch to my students was that the Monte Carlo approach would provide a deeper understanding of the issues raised by hierarchical models.
The basic feedback from students was that, in the short time available for the class, they were able to get a deeper understanding of HLMs than if the class had be structured as a conventional statistics class (math lectures and exercises?). One student comment in the course evaluations that s/he "...wished all stat classes were taught this way." For better or worse, my classes always have been.
If you are interested in the topic and want to follow the serialization in future postings, I will try to follow my lectures, which were live programming demonstrations, as closely as possible keeping in mind some of the questions and problems my students had when confronting the material.
NOTE: Assuming you have R installed on your machine and you have downloaded the files LibraryLoad.R and HLMprocedures.R to some folder on you local machine, you can load the libraries and procedures using the following commands in R:
> setwd(W)
> source(file="LibraryLoad.R")
> source(file="HLMprocedures.R")
Saturday, March 10, 2012
Six Useful Classes of Linear Models
 Statistics (or Sadistics as my students like to call it) is a difficult subject to teach with many seemingly unrelated and obscure concepts, many of which are listed under "Background Links" in the right-hand column. Compare Statistics to Calculus, another difficult topic for students. In the Calculus there are only three concepts: a differential, an integral and a limit. Statisticians could only dream of such simplicity and elegance (have you finished counting all the concepts listed on the right)?
Statistics (or Sadistics as my students like to call it) is a difficult subject to teach with many seemingly unrelated and obscure concepts, many of which are listed under "Background Links" in the right-hand column. Compare Statistics to Calculus, another difficult topic for students. In the Calculus there are only three concepts: a differential, an integral and a limit. Statisticians could only dream of such simplicity and elegance (have you finished counting all the concepts listed on the right)?
One way that has helped me bring some order to this chaos is to concentrate on the classes of models typically used by statisticians. The six major classes are displayed above in matrix notation (if you need a review on matrix algebra, try the one developed by George Bebis here). Clearly understanding each of the common linear models will also help classify Hierarchical Linear Models.
Equation (1) states simply that some matrix of dependent variables, Y, is the result of some multivariate distribution, E. The letter E is chosen since this distribution will eventually become an error distribution. The subscript, i, denotes that there can be multiple models for different populations--a really important distinction.
 Before leaving model (1) it is important to emphasize that we believe our dependent variables have some distribution. Consider the well-known distribution of Intelligence (IQ) displayed above (the "career potential" line in the graphic is a little hard to take; I know many police officers with higher intelligence than lawyers, but at least the graphic didn't use the "moron," "imbecile," and "idiot" classifications). It just so happens that the normal distribution that describes IQ is the same distribution that describes E in many cases. The point is that most dependent variables have a unimodal distribution that looks roughly bell-shaped. And, there are some interesting ways to determine a reasonable distribution for your dependent variable that I will cover in future posts.
Before leaving model (1) it is important to emphasize that we believe our dependent variables have some distribution. Consider the well-known distribution of Intelligence (IQ) displayed above (the "career potential" line in the graphic is a little hard to take; I know many police officers with higher intelligence than lawyers, but at least the graphic didn't use the "moron," "imbecile," and "idiot" classifications). It just so happens that the normal distribution that describes IQ is the same distribution that describes E in many cases. The point is that most dependent variables have a unimodal distribution that looks roughly bell-shaped. And, there are some interesting ways to determine a reasonable distribution for your dependent variable that I will cover in future posts.
Equation (2) is the classical linear model where X is a matrix of fixed-effect, independent variables and B is a matrix of unknown coefficients that must be estimated. There are many ways to estimate B, adding further complexities to statistics, but least squares is the standard approach (I'll cover all the different approaches in future posts). Notice also that once B is estimated, E = Y - XB by simple subtraction. The important point to emphasize here, a point that is often ignored in practice, is that X is fixed either by the researcher or is fixed under sampling. For example, if we think that IQ might affect college grade point (GPA) as in the model introduce here, then we have to sample equal numbers of observations across the entire range of IQ, from below 70 to above 130. Of course, that doesn't make sense since people with low IQ do not usually get into college. The result of practical sampling restrictions, however, might change the shape of the IQ distribution, creating another set of problems. Another way that the independent variables can be fixed is through assignment. When patients are assigned to experimental and control groups in clinical trials, for example, each group is given a [0,1] dummy variable classification (one if you are in the group, zero if not). Basically, the columns of X must each contain continuous variables such as IQ or dummy variables for group assignments.
Equations (3-6) start lifting the restriction on fixed independent variables. In Equation (3), the random (non-fixed) variables are contained in the matrix Z with it's own set of coefficients, A, that have to be estimated. Along with the coefficients, random variables have variances that also must be estimated, thus model (3) is called the random effects model. Typically, hierarchical linear models are lumped in with random effects models but in future posts and at the end of this post, I will argue that the two types of models should be thought of separately.
Equation (4) is the two-stage least squares model often used for simultaneous equation estimation in economics. Here, one of the dependent variables, y, is singled out as of primary interest even though there are other endogenous variables, Y, that are simultaneously related to y. Model (4) describes structural equation models (SEMs, introduced in a previous post here) as typically used in economics. The variables in X are considered exogenous variables or predetermined variables meaning that any predictions from model (4) are generally restricted to the available values of X. Again, there are a number of specialized estimation techniques for the two-stage least squares model.
Equation (5) is the path analytic model used in both Sociology and Economics. In the path analytic SEM, all the Y variables are considered endogenous. Both model (4) and model (5) bring up the problem of identification which I will cover in a future post. Again, there are separate techniques for the estimation of parameters in model (5). There are also a whole range of controversies surrounding SEMs and causality that I will also discuss in future posts. For the time being, it is important to point out that model (5) starts to look at the unit of analysis as a system that can be described with linear equations.
Finally, Equation (6) describes the basic time series model as an n-th order difference equation. The Y matrix, in this case, has a time ordering (t and t-1) where the Y's are considered output variables and the X's are considered input variables. Time series models introduce a specific type of causality called Granger causality, for the economist Clive Granger. In model (6) the Y(t-1) variables are considered fixed since values of variables in the past have already been determined. However, the errors in E can be correlated over time introducing the concept of autocorrelation. Also, since time series variables tend to move together over time (think of population growth and the growth of Gross National Product), time series causality can be confounded by cointegration, a problem that was also studied extensively by Clive Granger.
Models (1-6) don't exhaust all the possible models used in Statistics, but they do help classify the vast majority of problems currently being studied and do help us fix ideas and suggest topics for future posts. In the next post, my intention is to start with model (1) and describe the different types of distributions one typically finds in E and introduce some interesting approaches to determining the probable distribution of your data. These approaches differ from the typical null-hypothesis testing (NHT) approach (here) where you are required to test whether your data are normally distribution (Step 3, Testing Assumptions) before proceeding with conventional statistical tests (a topic I will also cover in a future post).
Finally, returning to the problem of hierarchical linear models (HLMs), the subscript i was introduced in models (1-6) because there is a hierarchical form of each model, not just model (3). The essential idea in HLMs (see my earlier post here) is that the unit of analysis is a hierarchical system with separate subpopulations (e.g., students, classrooms, hospitals, patients, countries, regions, etc.). Aspects of the subpopulations could be described by any of the models above. The area of multi-model inference (MMI) provides a more flexible approach to HLMs and solves the problems introduced by Simpson's paradox (described in an earlier post here).
MMI can be used successfully to determine an appropriate distribution for your data and help avoid the dead-end of NHT assumption testing. I'll cover the MMI approach to Equation (1) above in the next post. The important take away for this post is that determining the class or classes of models that are appropriate to your research question will help determine the appropriate type of analysis and types of assumptions that have to be made to complete the analysis.
Sunday, December 18, 2011
Multilevel Research Conceptual Problems: Wrong Level Fallacies
In a prior post on the definition of multi-level variables (here), I described two well known conceptual problems that can result from single-level analysis that uses aggregated and disaggregated data. The two problems, the atomistic fallacy and the ecological fallacy, will be discussed in more detail in this post. I will also discuss Simpson's paradox which is a similar fallacy that results from combining data.
 A simplified approach to random coefficient models (another name for HLMs) was introduced by Gumpertz and Pantula (here). In their approach, coefficients are first estimated within groups and then analyzed at the aggregate level with the estimated coefficients as data. One simple analysis would be to average the coefficients from each of the groups. The resulting regression curve (see the note below) is plotted above in green as the aggregate curve. Done this way, Simpson's paradox does not emerge.
A simplified approach to random coefficient models (another name for HLMs) was introduced by Gumpertz and Pantula (here). In their approach, coefficients are first estimated within groups and then analyzed at the aggregate level with the estimated coefficients as data. One simple analysis would be to average the coefficients from each of the groups. The resulting regression curve (see the note below) is plotted above in green as the aggregate curve. Done this way, Simpson's paradox does not emerge.
The atomistic and ecological fallacies involve the same problem taken from different perspectives in the hierarchy. When you formulate inferences at a higher level based on data gathered at a lower level, you can commit the atomistic fallacy. For example, it cannot be assumed that the negative relationship between infant mortality and individual income is the same at the individual level as at the country level. High income inequality might mediate the effect at the aggregate level.
Formulating inferences at a lower level from data measured at a higher level can commit the ecological fallacy. The issue is particularly important in medicine where health care providers attempt to treat individual patients based on aggregate data about treatment effectiveness. Individuals have much more variability than aggregate populations and relationships at the aggregate level can be reversed from what is appropriate at the lower level. I'll discuss a specific example involving kidney stone treatment below, but the issue becomes clearer when we consider the details of Simpson's Paradox.

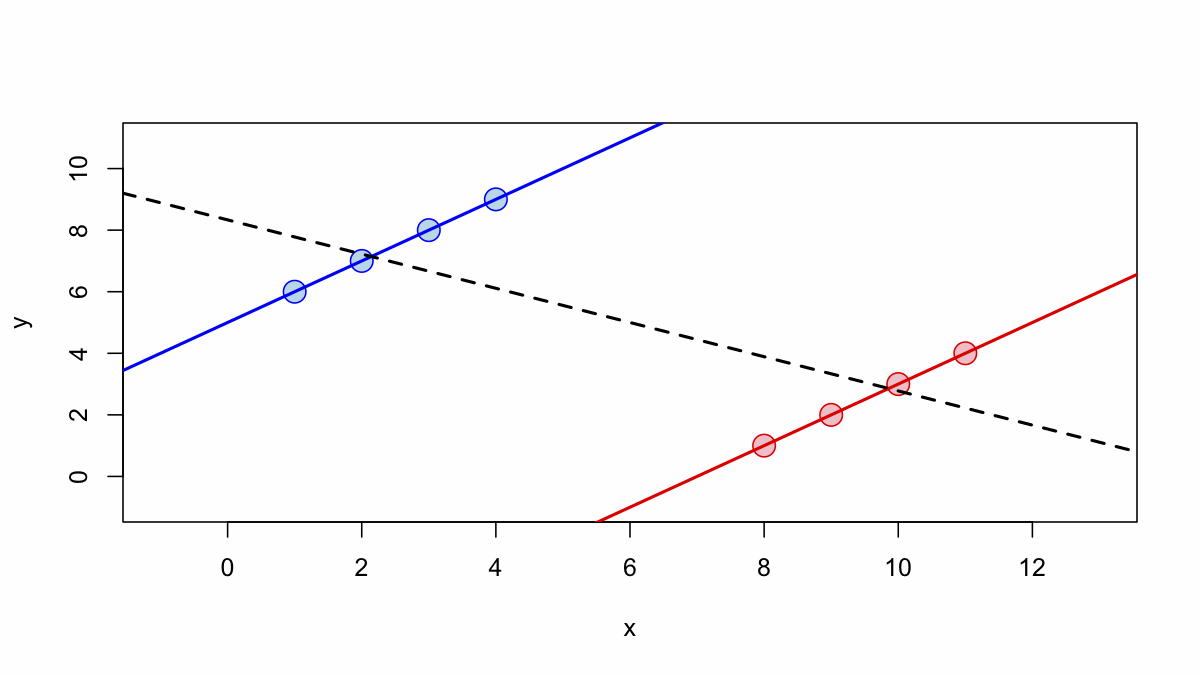
Simpson's paradox involves correlations present in different groups which are reversed when the groups are combined. Consider the graph presented above. In the subgroups there is a positive relationship between X and Y (for example, consider X height and Y income for two groups of males and females) . For the overall population (the dotted black line), however, the regression relationship is negative.
The reason for the paradoxical relationship is that there is a difference in the intercepts of the two groups. Not only are men taller as a group than women but they also have higher average income. The relationship at the aggregate level is based on the difference in intercepts in the regression equations from which the graphs were produced (see the note below explaining how the graphs were constructed).
 A simplified approach to random coefficient models (another name for HLMs) was introduced by Gumpertz and Pantula (here). In their approach, coefficients are first estimated within groups and then analyzed at the aggregate level with the estimated coefficients as data. One simple analysis would be to average the coefficients from each of the groups. The resulting regression curve (see the note below) is plotted above in green as the aggregate curve. Done this way, Simpson's paradox does not emerge.
A simplified approach to random coefficient models (another name for HLMs) was introduced by Gumpertz and Pantula (here). In their approach, coefficients are first estimated within groups and then analyzed at the aggregate level with the estimated coefficients as data. One simple analysis would be to average the coefficients from each of the groups. The resulting regression curve (see the note below) is plotted above in green as the aggregate curve. Done this way, Simpson's paradox does not emerge.
There are many real-world examples (here) of wrong level fallacies, all of which involve units of analysis within hierarchies:
- Civil Rights Act of 1964 Overall, more Republicans voted for the Act than Democrats, contrary to expectation. Legislators, however, are nested not only within States and parties but also regions. Regional affiliation turned out to be determinant with more Southern Democrats voting against the legislation.
- Kidney Stone Treatment Two treatments for Kidney stones (here) seemed to have similar rates of success. However, when the data were disaggregated by disease seriousness (the size of the kidney stones), one of the treatments produced better results. The problem here was that treatments were applied differentially based on case severity. This particular example of Simpson's paradox would typically be handled with a covariate for kidney stone size. The problem is to identify, with causal arguments, what that covariate should be. A multi-center clinical trial might have picked up the difference if case severity was not evenly distributed.
- Berkeley Gender Bias Aggregate data from admissions at UC Berkeley found bias in admission of women (here). When the data were disaggregated by department (recognizing the hierarchical organization of departments within academic institutions), it was found that there was a slight bias in favor of admitting women.
- Prenatal Care and Infant Survival Bishop et. al (1975, pp. 41-42, here) provide an example involving prenatal care and infant survival. The apparent association disappears when data are considered separately for each clinic involved. In other words, there was an overall association when the actual hierarchy (infants within clinics) was ignored.
Judea Pearl (here) has argued that fallacies such as Simpson's paradox cannot be resolved by statistical techniques. Pearl's argument, based on directed graphs, does not specifically included references to hierarchical models. Since HLMs are specifically designed to handle groups nested within higher order systems, HLMs hold out the possibility of providing the necessary theoretical rationale called for when identifying causal variables. I'll cover Pearl's argument and directed graph representations in a future post.
NOTE: The graphs above were produced in R and involve, in the first graph, three regression equations where the reversal is demonstrated (see the code here). The reversal disappears when group is included in the regression equation (see the R code here).
Multilevel Research: Definition of Variables

In a prior post (here), I described a typical hierarchical data structure of students nested within classrooms, nested within schools, nested within districts. Terminology has developed for describing types of variables at different levels in the hierarchy.
The typology in the graphic above was taken from Hox (2000, here) and Hox (1995, here) which was originally taken from Lazarsfield and Menzel (1961, here):
- Global or absolute variables refer only to the level at which they are defined, e.g., student intelligence or gender.
- Relational variables belong to one single level but describe relationships to other units of analysis at the same level. Sociometric status, for example, measures the extent to which someone is liked or disliked by their peers.
- Analytical variables are constructed from variables at a lower level. School mean achievement, for example, would refer to the achievement levels of students measured at the lower level and aggregated upward. Statistics other than means can also be used, for example, standard deviations to measure heterogeneity.
- Structural variables refer to the distribution of relational variables at the lower level. Social network indices (such as social capital) are one example.
- Contextual variables refer to the higher-level units. All units in the lower level receive the value of the higher level variable referring to the "context" of the units being measured.
It should be clear that constructing analytic or structural variables involves aggregation and that contextual variables involve disaggregation. In the graphic above, aggregation is noted by the right facing arrow, ->, while disaggregation is denoted with a left facing arrow, <-.
The ability to aggregate or disaggregate variables would seem to suggest that variables from different levels could variously be aggregated and disaggregated to perform a straight-forward single-level analysis. Two problems arise, however, that help motivate the application of multi-level techniques:
- Statistical Aggregated variables lose information in the aggregation process and result in lower statistical power at the higher level, that is, real significant results can fail to be identified (Type II Error). Disaggregated variables, on the other hand, tend to result in the identification of "significant" results that are totally spurious (Type I Error).
- Conceptual If results based on aggregate data are not interpreted carefully, conclusions at the higher level can be spurious (wrong level fallacy). Formulating inferences at a higher level based on data gathered at a lower level can commit the atomistic fallacy. Formulating inferences at a lower level from data measured at a higher level can commit the ecological fallacy.
Conceptual problems (wrong level fallacies) will be discussed in more detail in a future post. For the present, it is important to note that multi-level techniques that preserve the hierarchical structure of the data (even with aggregated and disaggregated variables in the analysis) seek to avoid the conceptual errors that can be made when the entire analysis is performed with aggregated and disaggregated variables at one level. An important question is how well the HLM techniques protect against wrong level fallacies.
Friday, December 16, 2011
Hierarchical Linear Models, Overview

Hierarchical Linear Models (HLMs) offer specialized statistical approaches to data that are organized in a hierarchy. A typical example (above) is pupils nested within classes, nested within schools, nested within school districts. If your research explores the relationship between individuals and society, HLMs will be of interest.
A conventional analysis of a hierarchical data set might (1) ignore the hierarchy and just sample students or (2) include indicator or dummy variables for the class, schools and district within which lower levels are nested. The issues raised by HLMs involve understanding the effects of either including or failing to include hierarchical effects and how precisely the effects are included.



For OLS, the assumption is that there is a single variance for all the normally distributed observations (the term on the left above should be read that the error terms are distributed normally with mean zero and the same variance for all observations where n is the number of observations and I is an identity matrix). For the weighted least squares model, there is an added matrix of weights, upper case sigma, that accounts for the different variances and covariances among the individual error terms. The variability in the variances is called heteroscedasticity and can be tested with Levene's test.
HLMs have been around under different names (mixed models, random effects models, variance components models, nested models, multi-level models, etc.) since the beginning of modern statistics but have only recently become popular in the 1990s. This is a little strange since it is hard to think of a unit of analysis one might study that is not nested within some hierarchy (think about patients, countries, firms, workers, etc.). It should also be pointed out that individuals are not always the lowest level of analysis; roles and repeated observations on individuals have also be used to define the lowest level.
Why have HLMs only recently become popular? I can offer three reasons: (1) The slow (very slow) diffusion of ideas from General Systems Theory (GST). Entire academic disciplines have developed around atomistic ideas describing their units of analysis (think of homo economicus in Economics). The ideas of GST have, understandably, met with a lot of resistance. And, let's face it, analyzing systems is more difficult than analyzing individuals and who said analyzing individuals was easy in any event. (2) The world is becoming more interconnected. In a globalized world, systems become more important and more determinant. And, (3) probably most importantly, software is now available in the major statistical packages (HLM, SAS, SPSS, STATA, and R).
This does not mean, however, that studies conducted using atomistic (pooled) analysis are wrong. If the hierarchy doesn't affect the unit of analysis you are studying, parsimony suggests that you ignore it. In other words, a case always has to be made that HLMs are appropriate to your sample. And, there is some evidence that misapplication of HLMs can obscure otherwise significant results.
Consider the simple two level linear model.

The lower case letters, a and b, are the first level ordinary least squares (OLS) parameters, the epsilon is the first-level error term, Y is the dependent variable and Z is the independent variable. At the second level, the gammas are the second-level parameters, W is the second-level dummy variable(s) and the mu's are the second level error terms. Notice that the first level parameters, a and b, are modeled as a function of the higher-level system effects.
Just to keep things simple, I'll assume that the higher-level systems only affect the intercept terms in the model.
After substitution, it's easy to see that we added a separate error term, mu. Adding more error can have the effect, if the added error is large, of obscuring otherwise significant effects.
Another way to see this is to look at the distributional assumptions.
For OLS, the assumption is that there is a single variance for all the normally distributed observations (the term on the left above should be read that the error terms are distributed normally with mean zero and the same variance for all observations where n is the number of observations and I is an identity matrix). For the weighted least squares model, there is an added matrix of weights, upper case sigma, that accounts for the different variances and covariances among the individual error terms. The variability in the variances is called heteroscedasticity and can be tested with Levene's test.
Basically, HLMs handle heteroscedasticity by estimating the error components and then dividing out the error with some form of Generalized Least Squares (GLS). However, if the variances are large compared to the estimated parameters (think t-statistics), significant effects can obscured.
In future posts, I'll go through some of the issues raised by HLMs in much more detail. Here's a partial list of the issues as I currently understand them:
- Are HLMs enhancing theory or are they just methodologies for partitioning variance?
- What is the sampling model underlying HLMs and what does it imply for statistical conclusions? Are we sampling at each level in the hierarchy or just the lowest level? If so, what are the consequences of sampling only at the lowest level?
- What are the implications of analyses derived from multi-level research? For example, does hierarchical analysis imply, in the example above, that students could be transferred to different classes, different schools and different districts and have, for example, improved academic performance? What if the new school, for example, is not in the sample. How is it to be coded as a new dummy variable in the model?
- What is the meaning of aggregated variables? For example, can we aggregate student intelligence scores to the school level and move the intelligence variable to a higher level? How do we interpret such aggregation?
- Does statistical power analysis at the individual level cover HLMs or is some other approach needed (power analysis determines how large a sample is necessary to observe a significant result)?
- There are many methods by which hierarchical analysis can be conducted, from simple to very complex. How well do these various approaches compare to each other and compare to a naive pooled analysis?
- How powerful are the tests for heteroscedasticity, that is, can these tests be relied on to tell us when HLMs are appropriate?
In future posts I'll go through a presentation by Doug Bates, an expert on HLMs at UW Madison, from a workshop he gave at University of Lausanne in 2009 (here). It's an excellent presentation and it gives me the opportunity to explore the questions raised above.
Next summer, I might have an opportunity to teach HLMs at the University of Tennessee in Knoxville. A tentative description of the course is listed below. Blog postings will basically allow me to serialize my lecture notes.
STATISTICAL ANALYSIS OF HIERARCHICAL LINEAR MODELS
Hierarchical linear models (HLMs) allow researchers to locate units of analysis within hierarchical systems, for example, students within school systems, patients within treatment facilities, firms within industries, states within federal governments, countries within regions, regions within the world system, etc. In fact, it would be rare to find a unit of analysis that was not situated within some higher-order system. This does not mean that HLMs can be applied indiscriminantly. If higher-order systems are not contributing significant variation to your unit of analysis, HLMs can obscure otherwise signifiant effects. This course will take a critical look at HLMs using computer intensive techniques for evaluating alternative estimators. The course will cover both parametric and nonparametric estimators to include the classes of OLS, WLS and GLS estimators, tests for homogeneity of variance and normality, statistical power analysis, the EM algorithm, classes of ML estimators, the bootstrap and rank transformation (RT) models. As a course project, students will do either a comparative methodological study or analyze an existing hierarchical data set. The R statistical package will be used for in-class demonstrations and method studies. For data analysis, students can either work in R or other available packages with HLM capabilities (SAS, SPSS, HLM, Stata, etc.). A course in regression analysis and basic computer literacy are prerequisites. Bring your laptop computer to class and, if possible, have R installed on your machine. R is free and can be obtained from http://www.r-project.org/.
Subscribe to:
Comments (Atom)