The atomistic and ecological fallacies involve the same problem taken from different perspectives in the hierarchy. When you formulate inferences at a higher level based on data gathered at a lower level, you can commit the atomistic fallacy. For example, it cannot be assumed that the negative relationship between infant mortality and individual income is the same at the individual level as at the country level. High income inequality might mediate the effect at the aggregate level.
Formulating inferences at a lower level from data measured at a higher level can commit the ecological fallacy. The issue is particularly important in medicine where health care providers attempt to treat individual patients based on aggregate data about treatment effectiveness. Individuals have much more variability than aggregate populations and relationships at the aggregate level can be reversed from what is appropriate at the lower level. I'll discuss a specific example involving kidney stone treatment below, but the issue becomes clearer when we consider the details of Simpson's Paradox.

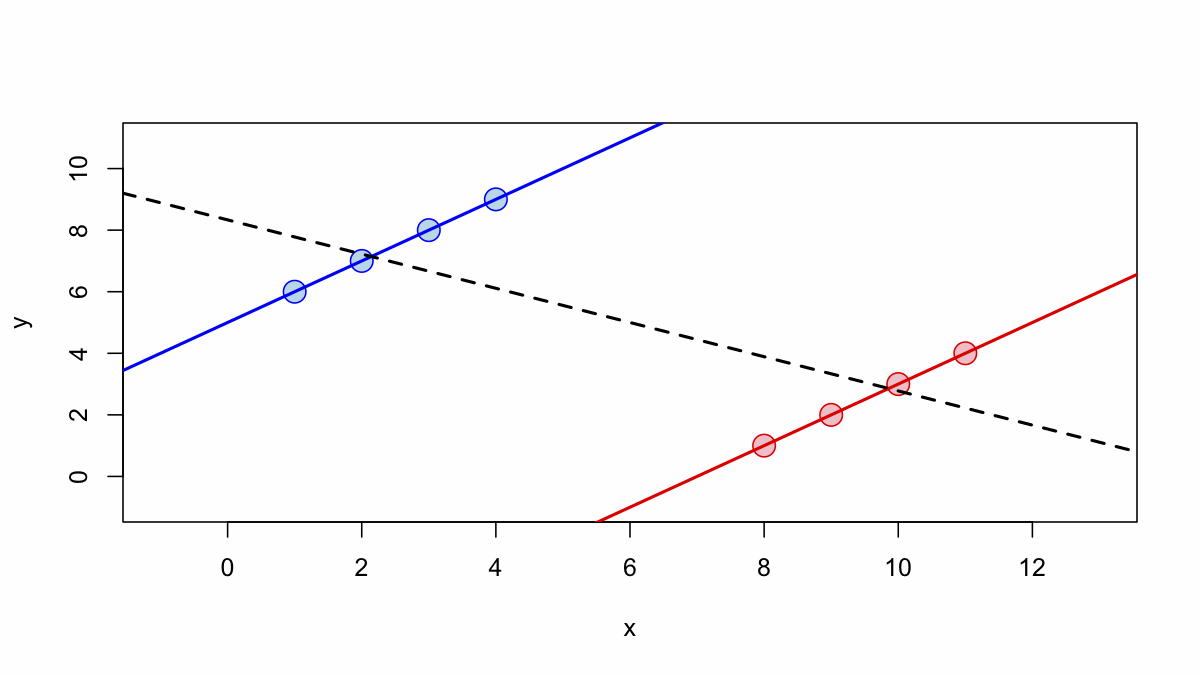
Simpson's paradox involves correlations present in different groups which are reversed when the groups are combined. Consider the graph presented above. In the subgroups there is a positive relationship between X and Y (for example, consider X height and Y income for two groups of males and females) . For the overall population (the dotted black line), however, the regression relationship is negative.
The reason for the paradoxical relationship is that there is a difference in the intercepts of the two groups. Not only are men taller as a group than women but they also have higher average income. The relationship at the aggregate level is based on the difference in intercepts in the regression equations from which the graphs were produced (see the note below explaining how the graphs were constructed).
 A simplified approach to random coefficient models (another name for HLMs) was introduced by Gumpertz and Pantula (here). In their approach, coefficients are first estimated within groups and then analyzed at the aggregate level with the estimated coefficients as data. One simple analysis would be to average the coefficients from each of the groups. The resulting regression curve (see the note below) is plotted above in green as the aggregate curve. Done this way, Simpson's paradox does not emerge.
A simplified approach to random coefficient models (another name for HLMs) was introduced by Gumpertz and Pantula (here). In their approach, coefficients are first estimated within groups and then analyzed at the aggregate level with the estimated coefficients as data. One simple analysis would be to average the coefficients from each of the groups. The resulting regression curve (see the note below) is plotted above in green as the aggregate curve. Done this way, Simpson's paradox does not emerge.
There are many real-world examples (here) of wrong level fallacies, all of which involve units of analysis within hierarchies:
- Civil Rights Act of 1964 Overall, more Republicans voted for the Act than Democrats, contrary to expectation. Legislators, however, are nested not only within States and parties but also regions. Regional affiliation turned out to be determinant with more Southern Democrats voting against the legislation.
- Kidney Stone Treatment Two treatments for Kidney stones (here) seemed to have similar rates of success. However, when the data were disaggregated by disease seriousness (the size of the kidney stones), one of the treatments produced better results. The problem here was that treatments were applied differentially based on case severity. This particular example of Simpson's paradox would typically be handled with a covariate for kidney stone size. The problem is to identify, with causal arguments, what that covariate should be. A multi-center clinical trial might have picked up the difference if case severity was not evenly distributed.
- Berkeley Gender Bias Aggregate data from admissions at UC Berkeley found bias in admission of women (here). When the data were disaggregated by department (recognizing the hierarchical organization of departments within academic institutions), it was found that there was a slight bias in favor of admitting women.
- Prenatal Care and Infant Survival Bishop et. al (1975, pp. 41-42, here) provide an example involving prenatal care and infant survival. The apparent association disappears when data are considered separately for each clinic involved. In other words, there was an overall association when the actual hierarchy (infants within clinics) was ignored.
Judea Pearl (here) has argued that fallacies such as Simpson's paradox cannot be resolved by statistical techniques. Pearl's argument, based on directed graphs, does not specifically included references to hierarchical models. Since HLMs are specifically designed to handle groups nested within higher order systems, HLMs hold out the possibility of providing the necessary theoretical rationale called for when identifying causal variables. I'll cover Pearl's argument and directed graph representations in a future post.
NOTE: The graphs above were produced in R and involve, in the first graph, three regression equations where the reversal is demonstrated (see the code here). The reversal disappears when group is included in the regression equation (see the R code here).
No comments:
Post a Comment